Используйте имена динамических диапазонов в Excel для гибких раскрывающихся списков
Электронные таблицы Excel(Excel) часто содержат раскрывающиеся списки ячеек для упрощения и/или стандартизации ввода данных. Эти раскрывающиеся списки создаются с использованием функции проверки данных, чтобы указать список допустимых записей.
Чтобы настроить простой раскрывающийся список, выберите ячейку, в которую будут вводиться данные, затем нажмите « Проверка данных(Data Validation) » (на вкладке « Данные(Data) »), выберите « Проверка данных(Data Validation) » , выберите « Список»(List) (в разделе « Разрешить(Allow) :)», а затем введите элементы списка (разделенные запятыми). ) в поле Источник(Source) : (см. рис. 1).
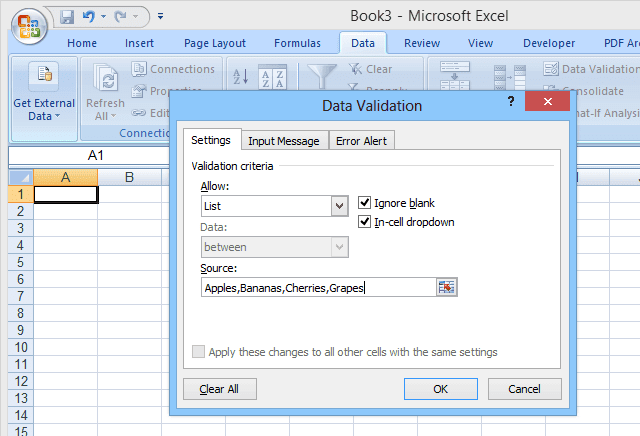
В базовом раскрывающемся списке этого типа список допустимых записей указывается в самой проверке данных; поэтому, чтобы внести изменения в список, пользователь должен открыть и отредактировать проверку данных. Однако это может быть сложно для неопытных пользователей или в случаях, когда список вариантов длинный.
Другой вариант — поместить список в именованный диапазон в электронной таблице(named range within the spreadsheet) , а затем указать имя этого диапазона (с префиксом знака равенства) в поле « Источник(Source) :» проверки данных (как показано на рис. 2(Figure 2) ).

Этот второй метод упрощает редактирование вариантов в списке, но добавление или удаление элементов может быть проблематичным. Поскольку именованный диапазон ( FruitChoices , в нашем примере) относится к фиксированному диапазону ячеек ($H$3:$H$10, как показано), если в ячейки (FruitChoices)H11 или ниже добавить дополнительные варианты , они не будут отображаться в раскрывающемся списке. (поскольку эти ячейки не входят в диапазон FruitChoices ).
Аналогичным образом, если, например, записи « Груши(Pears) » и « Клубника(Strawberries) » удалены, они больше не будут отображаться в раскрывающемся списке, а вместо этого в раскрывающемся списке будут два «пустых» варианта, поскольку раскрывающийся список по-прежнему ссылается на весь диапазон FruitChoices, включая пустые ячейки H9 и Н10(H10) .
По этим причинам при использовании обычного именованного диапазона в качестве источника списка для раскрывающегося списка необходимо отредактировать сам именованный диапазон, чтобы он включал больше или меньше ячеек, если записи добавляются или удаляются из списка.
Решением этой проблемы является использование имени динамического(dynamic) диапазона в качестве источника для выбора в раскрывающемся списке. Имя динамического диапазона автоматически расширяется (или сжимается), чтобы точно соответствовать размеру блока данных при добавлении или удалении записей. Для этого вы используете формулу(formula) , а не фиксированный диапазон адресов ячеек, чтобы определить именованный диапазон.
Как настроить динамический диапазон(Dynamic Range) в Excel
Обычное (статическое) имя диапазона относится к указанному диапазону ячеек ($H$3:$H$10 в нашем примере, см. ниже):

Но динамический диапазон определяется с помощью формулы (см. ниже, взятой из отдельной электронной таблицы, в которой используются имена динамических диапазонов):

Прежде чем мы начнем, обязательно загрузите наш файл примера Excel (макросы сортировки отключены).
Рассмотрим эту формулу подробно. Выбор фруктов находится в блоке ячеек непосредственно под заголовком ( ФРУКТЫ(FRUITS) ). Этому заголовку также присваивается имя: FruitsHeading :

Полная формула, используемая для определения динамического диапазона для выбора фруктов , выглядит следующим образом:(Fruits)
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(OFFSET(FruitsHeading,1,0,20,1)),0,0),0)-1,20),1)
FruitsHeading относится к заголовку, который находится на одну строку выше первой записи в списке. Число 20 (используется в формуле два раза) — это максимальный размер (количество строк) списка (его можно настроить по желанию).
Обратите внимание, что в этом примере в списке всего 8 записей, но под ними есть пустые ячейки, куда можно добавить дополнительные записи. Число 20 относится ко всему блоку, в котором могут быть сделаны записи, а не к фактическому количеству записей.
Теперь давайте разобьем формулу на части (обозначив каждую часть цветом), чтобы понять, как она работает:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(OFFSET(FruitsHeading,1,0,20,1)),0,0),0)-1,20),1)
Самая «внутренняя» часть — OFFSET(FruitsHeading,1,0,20,1) . Это ссылка на блок из 20 ячеек (под ячейкой FruitsHeading ), в который можно вводить варианты. Эта функция OFFSET в основном говорит: начните с ячейки FruitsHeading , спуститесь на 1 строку и более 0 столбцов, затем выберите область длиной 20 строк и шириной 1 столбец. Таким образом, мы получаем блок из 20 строк, в который вводятся варианты фруктов .(Fruits)
Следующей частью формулы является функция ЕПУСТО(ISBLANK) :
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(the above),0,0),0)-1,20),1)
Здесь функция OFFSET (описанная выше) заменена на «вышеупомянутое» (для облегчения чтения). Но функция ЕПУСТО(ISBLANK) работает с 20-строчным диапазоном ячеек, который определяет функция СМЕЩ(OFFSET) .
Затем IПУСТО(ISBLANK) создает набор из 20 значений ИСТИНА(TRUE) и ЛОЖЬ(FALSE) , указывая, является ли каждая из отдельных ячеек в диапазоне из 20 строк, на который ссылается функция СМЕЩ , пустой (пустой) или нет. (OFFSET)В этом примере первые 8 значений в наборе будут FALSE , поскольку первые 8 ячеек не пусты, а последние 12 значений будут TRUE .
Следующая часть формулы — это функция ИНДЕКС :(INDEX)
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(the above,0,0),0)-1,20),1)
Опять же, «вышеупомянутое» относится к описанным выше функциям ЕПУСТО(ISBLANK) и СМЕЩЕНИЕ . (OFFSET)Функция ИНДЕКС(INDEX) возвращает массив, содержащий 20 значений TRUE / FALSEЕПУСТО(ISBLANK) .
ИНДЕКС(INDEX) обычно используется для выбора определенного значения (или диапазона значений) из блока данных путем указания определенной строки и столбца (внутри этого блока). Но установка входных данных строки и столбца равными нулю (как это сделано здесь) приводит к тому, что INDEX возвращает массив, содержащий весь блок данных.
Следующим элементом формулы является функция ПОИСКПОЗ(MATCH) :
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,the above,0)-1,20),1)
Функция ПОИСКПОЗ(MATCH) возвращает позицию первого значения ИСТИНА(TRUE) в массиве, возвращенном функцией ИНДЕКС . (INDEX)Так как первые 8 записей в списке не пустые, первые 8 значений в массиве будут FALSE , а девятое значение будет TRUE (поскольку 9 -я строка в диапазоне пуста).
Таким образом, функция ПОИСКПОЗ(MATCH) вернет значение 9 . Однако в данном случае мы действительно хотим знать, сколько элементов в списке, поэтому формула вычитает 1 из значения ПОИСКПОЗ(MATCH) (которое дает позицию последнего элемента). Таким образом, в конечном итоге MATCH ( TRUE ,вышеупомянутое,0)-1 возвращает значение 8 .
Следующая часть формулы — это функция ЕСЛИОШИБКА(IFERROR) :
=OFFSET(FruitsHeading,1,0,IFERROR(the above,20),1)
Функция ЕСЛИОШИБКА(IFERROR) возвращает альтернативное значение, если первое указанное значение приводит к ошибке. Эта функция включена, поскольку, если весь блок ячеек (все 20 строк) заполнен записями, функция ПОИСКПОЗ(MATCH) вернет ошибку.
Это связано с тем, что мы сообщаем функции ПОИСКПОЗ(MATCH) искать первое значение ИСТИНА(TRUE) (в массиве значений из функции ЕПУСТО(ISBLANK) ), но если НИ ОДНА(NONE) из ячеек не пуста, то весь массив будет заполнен значениями ЛОЖЬ(FALSE) . Если ПОИСКПОЗ(MATCH) не может найти целевое значение ( ИСТИНА(TRUE) ) в искомом массиве, он возвращает ошибку.
Итак, если весь список заполнен (и, следовательно, ПОИСКПОЗ(MATCH) возвращает ошибку), функция ЕСЛИОШИБКА(IFERROR) вместо этого вернет значение 20 (зная, что в списке должно быть 20 записей).
Наконец, OFFSET(FruitsHeading,1,0,the выше,1)(OFFSET(FruitsHeading,1,0,the above,1)) возвращает диапазон, который мы на самом деле ищем: начните с ячейки FruitsHeading , спуститесь на 1 строку и более чем на 0 столбцов, затем выберите область, длина которой равна количеству строк. в списке есть записи (и 1 столбец шириной). Таким образом, вся формула вместе вернет диапазон, содержащий только фактические записи (вплоть до первой пустой ячейки).
Использование этой формулы для определения диапазона, который является источником для раскрывающегося списка, означает, что вы можете свободно редактировать список (добавляя или удаляя записи, пока оставшиеся записи начинаются в верхней ячейке и являются смежными), и раскрывающийся список всегда будет отражать текущий список (см. рис. 6(Figure 6) ).

Используемый здесь файл примера (динамические списки) включен и доступен для загрузки с этого веб-сайта. Однако макросы не работают, потому что WordPress не любит книги Excel с макросами.
В качестве альтернативы указанию количества строк в блоке списка блоку списка можно присвоить собственное имя диапазона, которое затем можно использовать в модифицированной формуле. В файле примера второй список ( Names ) использует этот метод. Здесь всему блоку списка (под заголовком «NAMES», 40 строк в файле примера) назначается имя диапазона NameBlock . Тогда альтернативная формула для определения NamesList :
=OFFSET(NamesHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(NamesBlock),0,0),0)-1,ROWS(NamesBlock)),1)
где NamesBlock заменяет OFFSET ( FruitsHeading,1,0,20,1 ), а ROWS(NamesBlock) заменяет 20 (количество строк) в предыдущей формуле.
Итак, для выпадающих списков, которые можно легко редактировать (в том числе другими пользователями, которые могут быть неопытными), попробуйте использовать имена динамических диапазонов! И обратите внимание, что, хотя эта статья была посвящена раскрывающимся спискам, имена динамических диапазонов можно использовать везде, где вам нужно сослаться на диапазон или список, который может различаться по размеру. Наслаждаться!

About the author
«Я внештатный эксперт по Windows и Office. У меня более 10 лет опыта работы с этими инструментами, и я могу помочь вам извлечь из них максимальную пользу. Мои навыки включают в себя: работу с Microsoft Word, Excel, PowerPoint и Outlook; страницы и приложения, а также помощь клиентам в достижении их бизнес-целей».
Related posts
Как удалить пустые строки в Excel
Как использовать функцию «Говорить ячейки» в Excel
Как вставить лист Excel в документ Word
Как использовать анализ «что, если» в Excel
Как исправить строку в Excel
Подключение Excel к MySQL
Как использовать операторы If и вложенные операторы If в Excel
Как объединить ячейки, столбцы и строки в Excel
Как использовать Flash Fill в Excel
Как написать формулу/оператор ЕСЛИ в Excel
Как быстро вставить несколько строк в Excel
3 способа разделить ячейку в Excel
Используйте клавиатуру для изменения высоты строки и ширины столбца в Excel
Как рассчитать Z-показатель в Excel
Почему вы должны использовать именованные диапазоны в Excel
Как искать в Excel
2 способа использования функции транспонирования Excel
Когда использовать Index-Match вместо VLOOKUP в Excel
Как сделать круговую диаграмму в Excel
Группировать строки и столбцы на листе Excel